
Denoising to Future Trajs
Motion-aware Mamba is proposed to gradually denoise latent features in the latent diffusion to predict accurate hand waypoints.
MADiff is a pioneering Mamba diffusion model for hand trajectory prediction (HTP). It exploits the devised motion-aware Mamba for diffusion denoising. A novel motion-driven selective scan (MDSS) is tailored to facilitate state transition, capturing entangled hand motion and camera egomotion patterns with temporal causality.
Please refer to our paper for more details about the contributions of this work.
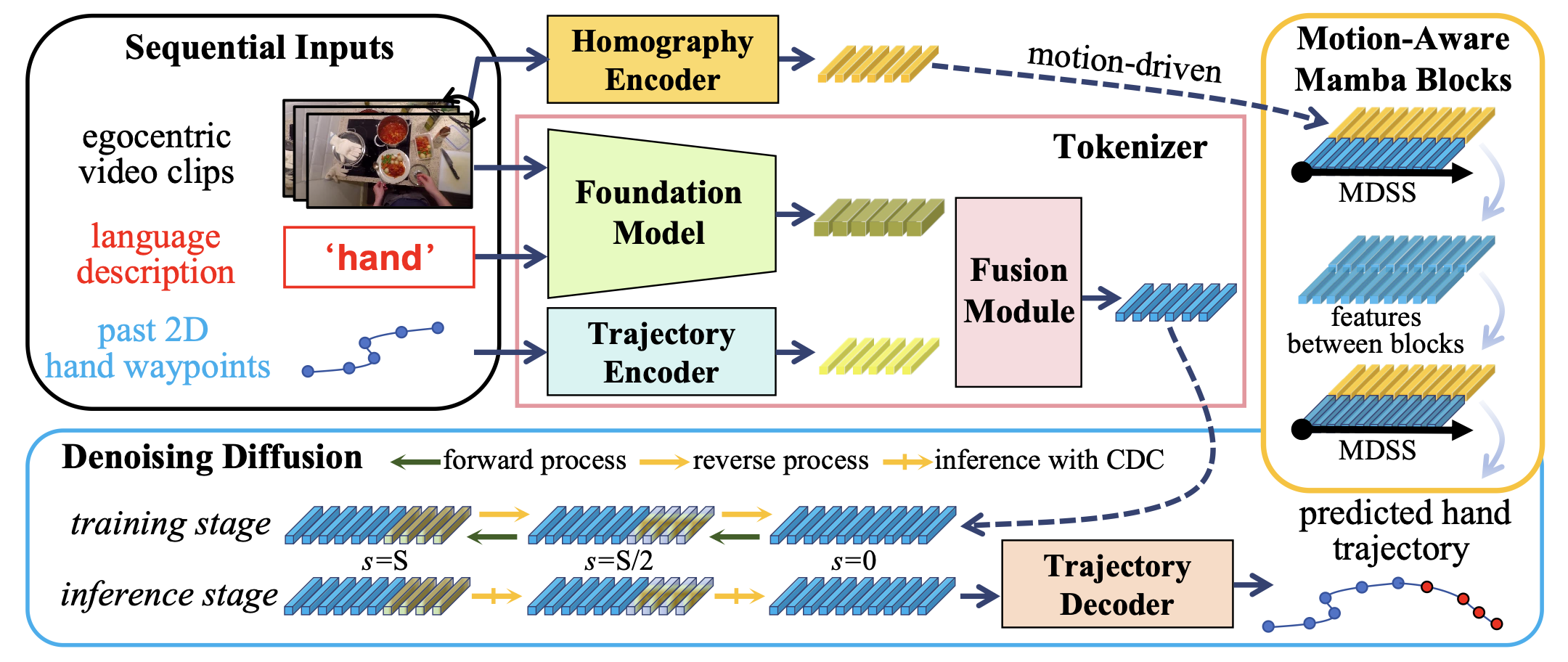
We use the foundation model for extracting semantic features sensitive to hand-scenario relationships. Visual grounding allows us to use text prompt to achieve task-specific.
Motion-aware Mamba is proposed to gradually denoise latent features in the latent diffusion to predict accurate hand waypoints.
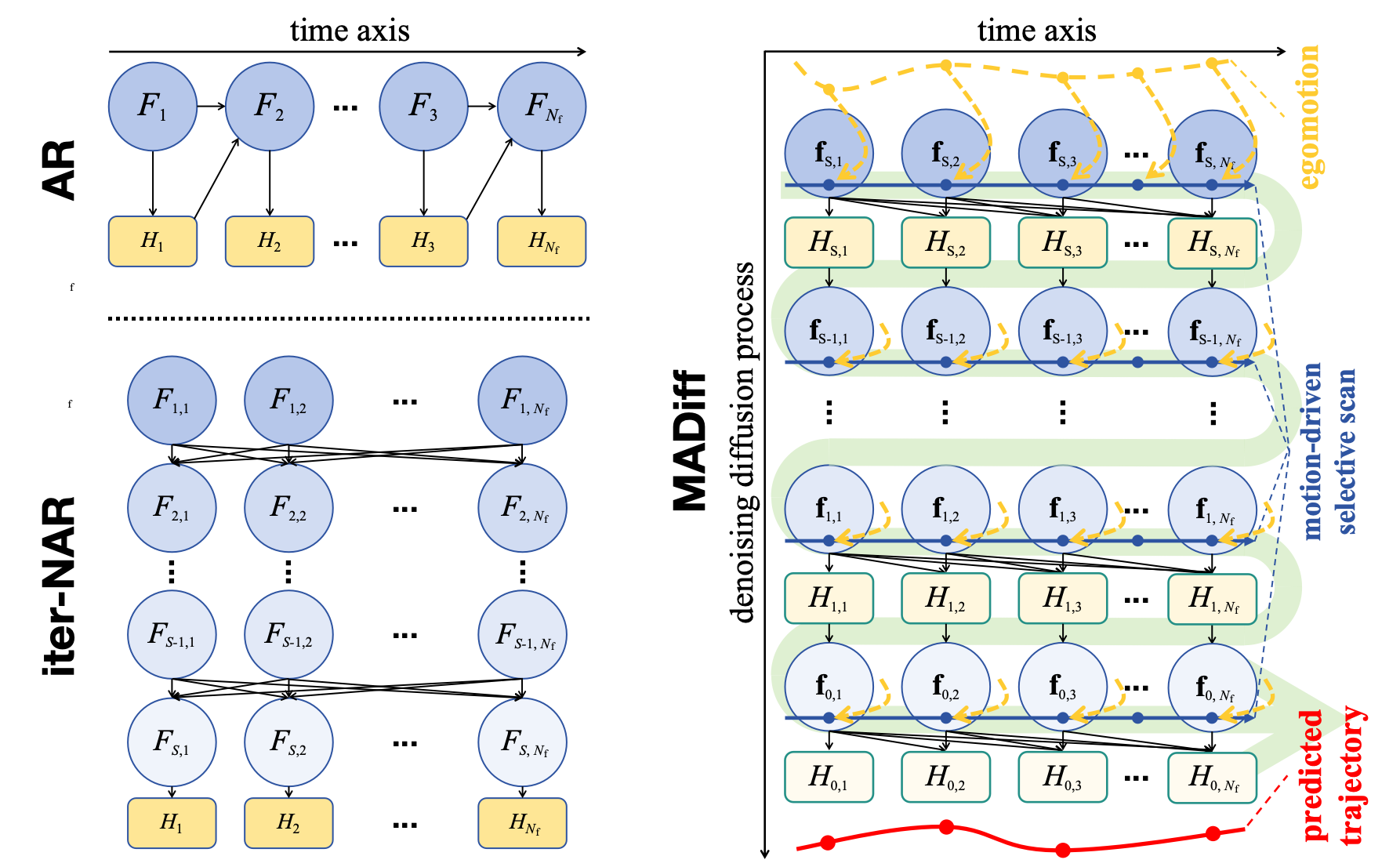
MDSS is proposed in our motion-aware Mamba to achieve diffusion denoising under egomotion guidance.
We use angle and length constraints to optimize the directionality and stabability of predicted hand trajectories.
The starting point of the predicted trajectory does not align with the hand in the image because here we use the first frame of the video clip as the prediction canvas, while the predicted trajectory’s starting point is at the timestamp close to the last frame of the video. Please refer to more results of comparison with baselines in our our paper.
MADiff follows a generative scheme and thus can generate trajectory clusters by multiple sampling from Gaussian noise.
The models agnostic to camera egomotion tend to accumulate prediction errors due to motion gaps increasing along the time axis. The final position and overall shape similarity are also not as good as those of the model with MDSS.
“hand”
“hand, which is scooping”
“hand”
“hand, which is throwing”
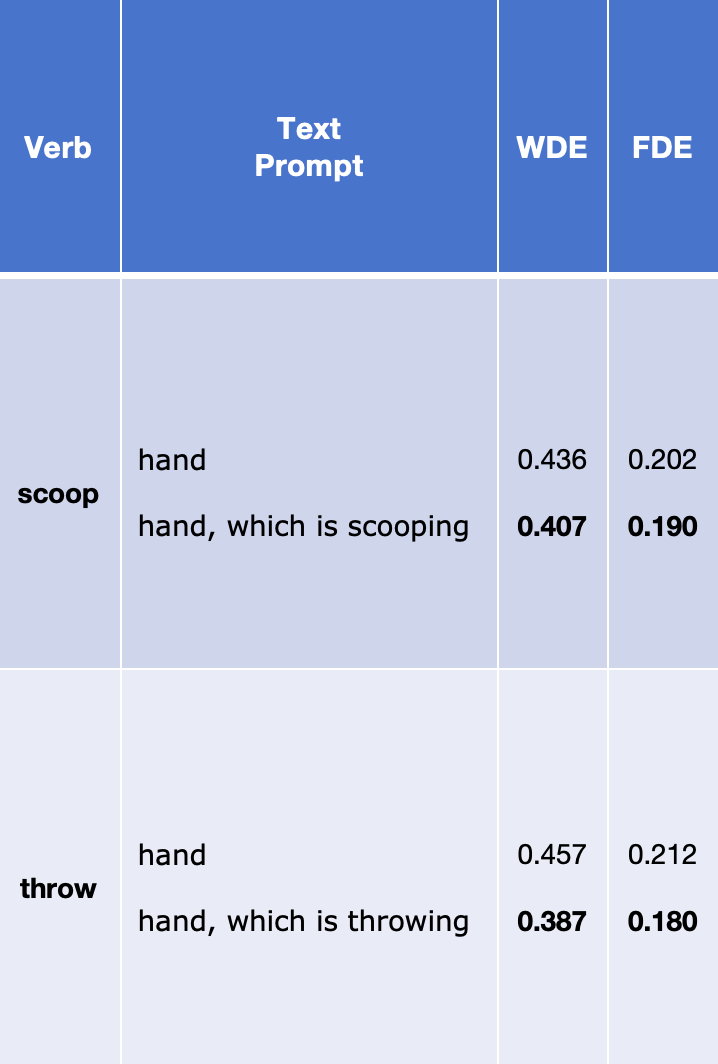
Text prompt tuning helps to extract action-specific semantics, thus improving corresponding HTP performance.
@misc{ma2024madiff,
title={MADiff: Motion-Aware Mamba Diffusion Models for Hand Trajectory Prediction on Egocentric Videos},
author={Junyi Ma and Xieyuanli Chen and Wentao Bao and Jingyi Xu and Hesheng Wang},
year={2024},
eprint={2409.02638},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2409.02638},
}